PDFelement - Edit, Annotate, Fill and Sign PDF Documents

Get from App Store
Sometimes you may want to change or edit your scanned PDF document for instance where you want to change the sizes of fonts and images or need to get text from PDF image. In this article, I will tell you the easiest way to extract text from PDF image.
To do it successfully you simply need to use the best text extractor for image PDF such as Wondershare PDFelement. This tool will help you perform OCR and edit your scanned PDF file the way you want. To add on this OCR feature is multilingual. It is able to recognize over 20 worldwide used languages.
Now let’s look at other features that this software exhibits:
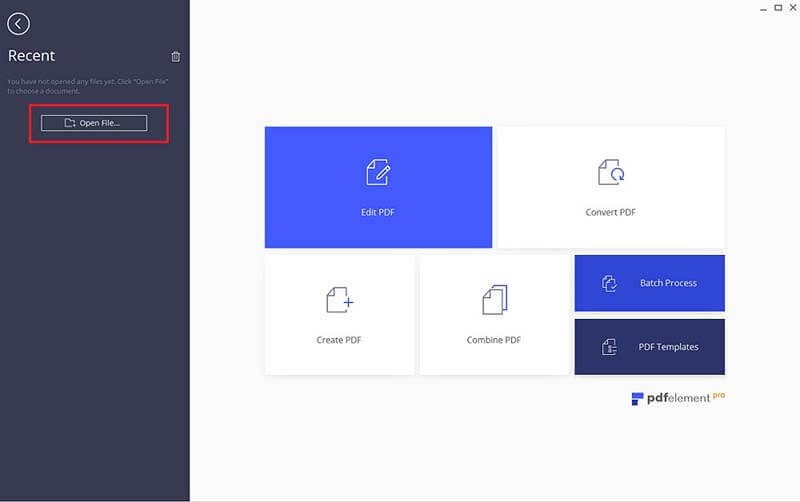
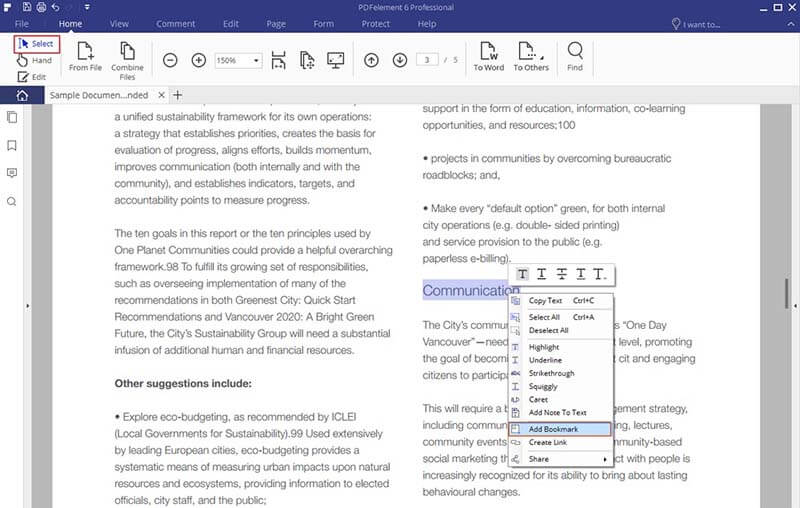
When you have installed PDFelement, you can now open it ready to perform OCR on your PDF. First run your Wondershare PDFelement and then click on "Open" to upload the scanned file to the program. Choose the right image based document.
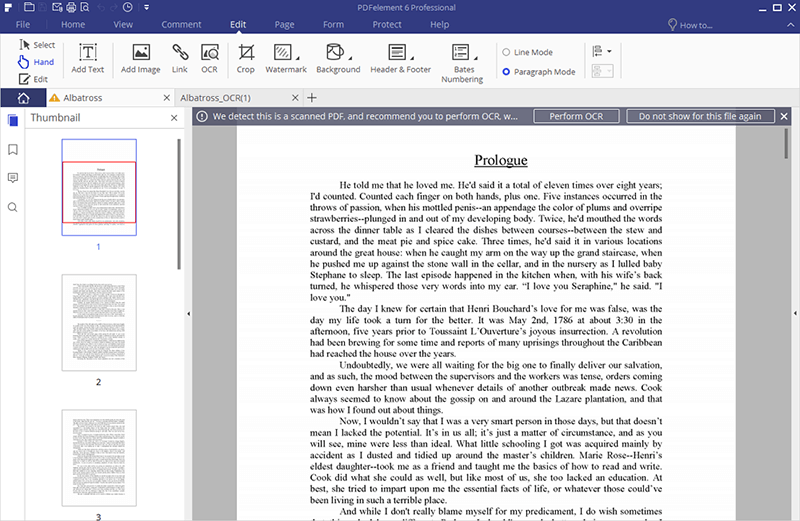
After you have opened the file on the program, it will detect that it is a scanned document hence you need to OCR it. Click on the "Perform OCR" option on the top yellow bar, then choose an OCR language and click "OK". It will be set English by default thus you can change it.
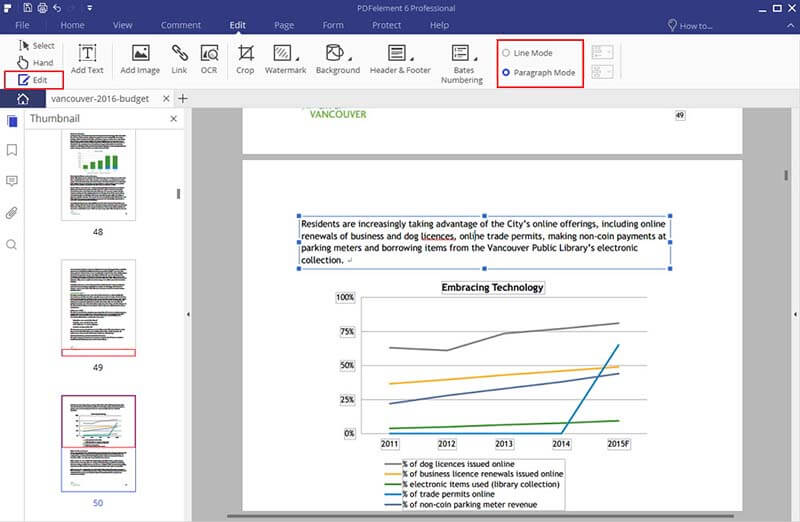
Once you have performed OCR, you then need to extract text from PDF. To do so, you can go to the "Edit" tab and click "Edit Text". Select the texts you need and right click to choose copy.
Alternatively, you can also convert your PDF to Word format. Click on the "To Word" button under the "Home" tab. In the pop up window, click on the "Convert" button to convert your PDF to Word format. You will now have your PDF in an editable format thus you can extract content from your newly converted file.

Still get confused or have more suggestions? Leave your thoughts to Community Center and we will reply within 24 hours.